update?
This commit is contained in:
@@ -1,2 +1,40 @@
|
|||||||
# CSE5519 Advances in Computer Vision (Topic B: 2021 and before: Vision-Language Models)
|
# CSE5519 Advances in Computer Vision (Topic B: 2021 and before: Vision-Language Models)
|
||||||
|
|
||||||
|
## Learning Transferable Visual Models From Natural Language Supervision
|
||||||
|
|
||||||
|
[link to the paper](https://arxiv.org/pdf/2103.00020)
|
||||||
|
|
||||||
|
By OpenAI. That's sick...
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Novelty in CLIP
|
||||||
|
|
||||||
|
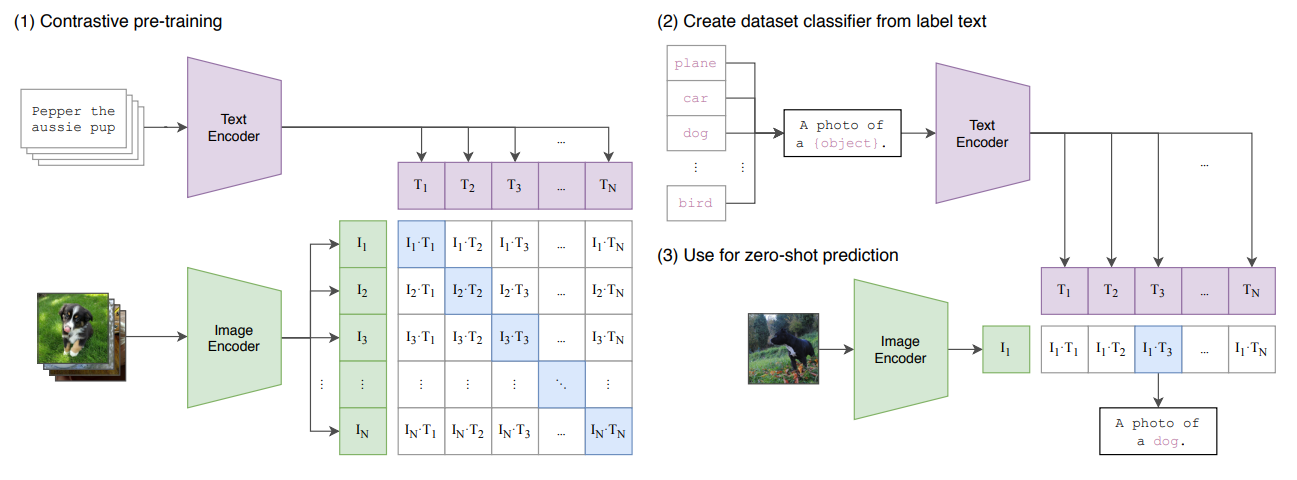
CLIP (Contrastive Language-Image Pre-training) is a simplified version of ConVIRT trained on large scale image-text pairs.
|
||||||
|
|
||||||
|
using natural language supervision for image representation learning.
|
||||||
|
|
||||||
|
Use more generalized image-caption pairs as supervision. (400 million (image, text) pairs collected from the internet)
|
||||||
|
|
||||||
|
No need to pre-train the model to fit ImageNet but predict with high accuracy on ImageNet.
|
||||||
|
|
||||||
|
This line of work represents the current pragmatic middle
|
||||||
|
ground between learning from a limited amount of supervised "gold-labels" and learning from practically unlimited amounts of raw text.
|
||||||
|
|
||||||
|
Use 5 version of ResNets and 3 version of ViTs as the base encoder. Then do standard attention-based contrastive learning to train the model.
|
||||||
|
|
||||||
|
### Prompt Engineering
|
||||||
|
|
||||||
|
"A photo of a {label}." to be a good default that helps specify the text is about the content of the image. This often improves performance over the baseline of using only the label text. For instance, just using this prompt improves accuracy on ImageNet by 1.3%.
|
||||||
|
|
||||||
|
### Limitations
|
||||||
|
|
||||||
|
we estimate around a 1000x increase in compute is required for zero-shot CLIP to reach overall state-of-the-art performance. This is infeasible to train with current hardware. Further research into improving upon the computational and data efficiency of CLIP will be necessary.
|
||||||
|
|
||||||
|
Zero-shot CLIP still generalizes poorly to data that is truly out-of-distribution for it.
|
||||||
|
|
||||||
|
> [!TIP]
|
||||||
|
>
|
||||||
|
> In defining the general task that CLIP can solve, and experimental results from Zero-Shot CLIP vs. Linear Probe on ResNet50. I can see that the performance of Zero-Shot CLIP is better than Linear Probe on ResNet50 on the tasks that are somehow "frequently labeled" by humans. For example, the car brand, the location of the image, etc. And perform badly when humans don't label the image or the idea is more abstract. For example, the distance of the camera, the numbers in the image, a satellite image of terrain, etc.
|
||||||
|
>
|
||||||
|
> Is the CLIP model really learning enough knowledge from the general natural language description of the image? If the description is more comprehensive, will CLIP outperform the Linear Probe on ResNet50?
|
||||||
|
|||||||
@@ -1,2 +1,14 @@
|
|||||||
# CSE5519 Advances in Computer Vision (Topic D: 2021 and before: Image and Video Generation)
|
# CSE5519 Advances in Computer Vision (Topic D: 2021 and before: Image and Video Generation)
|
||||||
|
|
||||||
|
## High-Resolution Image Synthesis with Latent Diffusion Models.
|
||||||
|
|
||||||
|
[link to the paper](https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf)
|
||||||
|
|
||||||
|
Image synthesis in high resolution.
|
||||||
|
|
||||||
|
### Novelty in Latent Diffusion Models
|
||||||
|
|
||||||
|
#### Transformer encoder for LDMs
|
||||||
|
|
||||||
|
use cross-attention to integrate the text embedding into the latent space.
|
||||||
|
|
||||||
|
|||||||
@@ -4,7 +4,7 @@
|
|||||||
>
|
>
|
||||||
> This site use [Algolia Search](https://www.algolia.com/) to search the content. However, due to some unknown reasons, when the index page is loaded, the search bar is calling default PageFind package from Nextra. **If you find the search bar is not working**, please try to redirect to another page and then back to the index page or search in another page.
|
> This site use [Algolia Search](https://www.algolia.com/) to search the content. However, due to some unknown reasons, when the index page is loaded, the search bar is calling default PageFind package from Nextra. **If you find the search bar is not working**, please try to redirect to another page and then back to the index page or search in another page.
|
||||||
>
|
>
|
||||||
> This site updates in a daily basis. But the sidebar is not. **If you find some notes are not shown on sidebar but the class already ends more than 24 hours**, please try to access the page directly via the URL. (for example, change the URL to `https://notenextra.trance-0.com/Math4201/Math4201_L{number}` to access the note of the lecture `Math4201_L{number}`)
|
> This site updates in a daily basis. But the sidebar is not. **If you find some notes are not shown on sidebar but the class already ends more than 24 hours**, please try to access the page directly via the URL. (for example, change the URL to `.../Math4201/Math4201_L{number}` to access the note of the lecture `Math4201_L{number}`)
|
||||||
|
|
||||||
This was originated from another project [NoteChondria](https://github.com/Trance-0/Notechondria) that I've been working on for a long time but don't have a stable release yet.
|
This was originated from another project [NoteChondria](https://github.com/Trance-0/Notechondria) that I've been working on for a long time but don't have a stable release yet.
|
||||||
|
|
||||||
|
|||||||
BIN
public/CSE5519/CLIP.png
Normal file
BIN
public/CSE5519/CLIP.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 108 KiB |
Reference in New Issue
Block a user