update
This commit is contained in:
215
pages/CSE559A/CSE559A_L21.md
Normal file
215
pages/CSE559A/CSE559A_L21.md
Normal file
@@ -0,0 +1,215 @@
|
|||||||
|
# CSE559A Lecture 21
|
||||||
|
|
||||||
|
## Continue on optical flow
|
||||||
|
|
||||||
|
### The brightness constancy constraint
|
||||||
|
|
||||||
|
$$
|
||||||
|
I_x u(x,y) + I_y v(x,y) + I_t = 0
|
||||||
|
$$
|
||||||
|
Given the gradients $I_x, I_y$ and $I_t$, can we uniquely recover the motion $(u,v)$?
|
||||||
|
|
||||||
|
- Suppose $(u, v)$ satisfies the constraint: $\nabla I \cdot (u,v) + I_t = 0$
|
||||||
|
- Then $\nabla I \cdot (u+u', v+v') + I_t = 0$ for any $(u', v')$ s.t. $\nabla I \cdot (u', v') = 0$
|
||||||
|
- Interpretation: the component of the flow perpendicular to the gradient (i.e., parallel to the edge) cannot be recovered!
|
||||||
|
|
||||||
|
#### Aperture problem
|
||||||
|
|
||||||
|
- The brightness constancy constraint is only valid for a small patch in the image
|
||||||
|
- For a large motion, the patch may look very different
|
||||||
|
|
||||||
|
Consider the barber pole illusion
|
||||||
|
|
||||||
|
### Estimating optical flow (Lucas-Kanade method)
|
||||||
|
|
||||||
|
- Consider a small patch in the image
|
||||||
|
- Assume the motion is constant within the patch
|
||||||
|
- Then we can solve for the motion $(u, v)$ by minimizing the error:
|
||||||
|
|
||||||
|
$$
|
||||||
|
I_x u(x,y) + I_y v(x,y) + I_t = 0
|
||||||
|
$$
|
||||||
|
|
||||||
|
How to get more equations for a pixel?
|
||||||
|
Spatial coherence constraint: assume the pixel’s neighbors have the same (𝑢,𝑣)
|
||||||
|
If we have 𝑛 pixels in the neighborhood, then we can set up a linear least squares system:
|
||||||
|
|
||||||
|
$$
|
||||||
|
\begin{bmatrix}
|
||||||
|
I_x(x_1, y_1) & I_y(x_1, y_1) \\
|
||||||
|
\vdots & \vdots \\
|
||||||
|
I_x(x_n, y_n) & I_y(x_n, y_n)
|
||||||
|
\end{bmatrix}
|
||||||
|
\begin{bmatrix}
|
||||||
|
u \\ v
|
||||||
|
\end{bmatrix} = -\begin{bmatrix}
|
||||||
|
I_t(x_1, y_1) \\ \vdots \\ I_t(x_n, y_n)
|
||||||
|
\end{bmatrix}
|
||||||
|
$$
|
||||||
|
|
||||||
|
#### Lucas-Kanade flow
|
||||||
|
|
||||||
|
Let $A=
|
||||||
|
\begin{bmatrix}
|
||||||
|
I_x(x_1, y_1) & I_y(x_1, y_1) \\
|
||||||
|
\vdots & \vdots \\
|
||||||
|
I_x(x_n, y_n) & I_y(x_n, y_n)
|
||||||
|
\end{bmatrix}$
|
||||||
|
|
||||||
|
$b = \begin{bmatrix}
|
||||||
|
I_t(x_1, y_1) \\ \vdots \\ I_t(x_n, y_n)
|
||||||
|
\end{bmatrix}$
|
||||||
|
|
||||||
|
$d = \begin{bmatrix}
|
||||||
|
u \\ v
|
||||||
|
\end{bmatrix}$
|
||||||
|
|
||||||
|
The solution is $d=(A^T A)^{-1} A^T b$
|
||||||
|
|
||||||
|
Lucas-Kanade flow:
|
||||||
|
|
||||||
|
- Find $(u,v)$ minimizing $\sum_{i} (I(x_i+u,y_i+v,t)-I(x_i,y_i,t-1))^2$
|
||||||
|
- use Taylor approximation of $I(x_i+u,y_i+v,t)$ for small shifts $(u,v)$ to obtain closed-form solution
|
||||||
|
|
||||||
|
### Refinement for Lucas-Kanade
|
||||||
|
|
||||||
|
In some cases, the Lucas-Kanade method may not work well:
|
||||||
|
- The motion is large (larger than a pixel)
|
||||||
|
- A point does not move like its neighbors
|
||||||
|
- Brightness constancy does not hold
|
||||||
|
|
||||||
|
#### Iterative refinement (for large motion)
|
||||||
|
|
||||||
|
Iterative Lukas-Kanade Algorithm
|
||||||
|
|
||||||
|
1. Estimate velocity at each pixel by solving Lucas-Kanade equations
|
||||||
|
2. Warp It towards It+1 using the estimated flow field
|
||||||
|
- use image warping techniques
|
||||||
|
3. Repeat until convergence
|
||||||
|
|
||||||
|
Iterative refinement is limited due to Aliasing
|
||||||
|
|
||||||
|
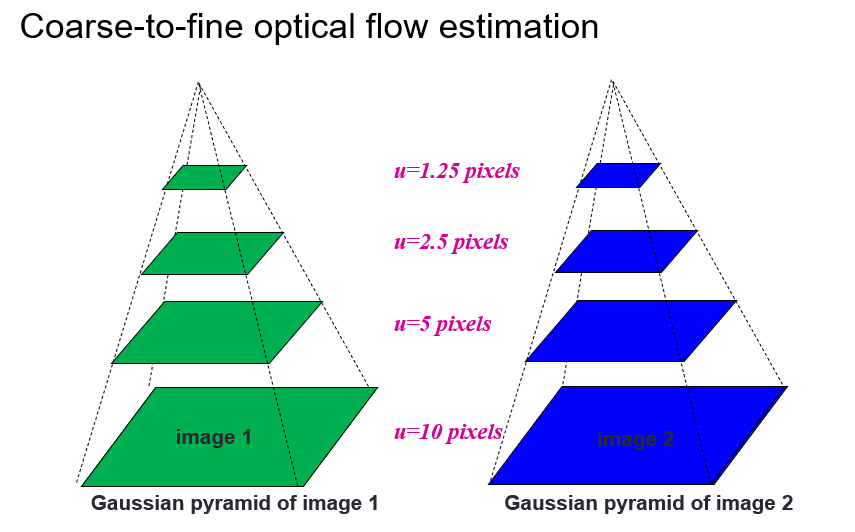
#### Coarse-to-fine refinement (for large motion)
|
||||||
|
|
||||||
|
- Estimate flow at a coarse level
|
||||||
|
- Refine the flow at a finer level
|
||||||
|
- Use the refined flow to warp the image
|
||||||
|
- Repeat until convergence
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### Representing moving images with layers (for a point may not move like its neighbors)
|
||||||
|
|
||||||
|
- The image can be decomposed into a moving layer and a stationary layer
|
||||||
|
- The moving layer is the layer that moves
|
||||||
|
- The stationary layer is the layer that does not move
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### SOTA models
|
||||||
|
|
||||||
|
#### 2009
|
||||||
|
|
||||||
|
Start with something similar to Lucas-Kanade
|
||||||
|
|
||||||
|
- gradient constancy
|
||||||
|
- energy minimization with smoothing term
|
||||||
|
- region matching
|
||||||
|
- keypoint matching (long-range)
|
||||||
|
|
||||||
|
#### 2015
|
||||||
|
|
||||||
|
Deep neural networks
|
||||||
|
|
||||||
|
- Use a deep neural network to represent the flow field
|
||||||
|
- Use synthetic data to train the network (floating chairs)
|
||||||
|
|
||||||
|
#### 2023
|
||||||
|
|
||||||
|
GMFlow
|
||||||
|
|
||||||
|
use Transformer to model the flow field
|
||||||
|
|
||||||
|
## Robust Fitting of parametric models
|
||||||
|
|
||||||
|
Challenges:
|
||||||
|
|
||||||
|
- Noise in the measured feature locations
|
||||||
|
- Extraneous data: clutter (outliers), multiple lines
|
||||||
|
- Missing data: occlusions
|
||||||
|
|
||||||
|
### Least squares fitting
|
||||||
|
|
||||||
|
Normal least squares fitting
|
||||||
|
|
||||||
|
$y=mx+b$ is not a good model for the data since there might be vertical lines
|
||||||
|
|
||||||
|
Instead we use total least squares
|
||||||
|
|
||||||
|
Line parametrization: $ax+by=d$
|
||||||
|
|
||||||
|
$(a,b)$ is the unit normal to the line (i.e., $a^2+b^2=1$)
|
||||||
|
$d$ is the distance between the line and the origin
|
||||||
|
Perpendicular distance between point $(x_i, y_i)$ and line $ax+by=d$ (assuming $a^2+b^2=1$):
|
||||||
|
|
||||||
|
$$
|
||||||
|
|ax_i + by_i - d|
|
||||||
|
$$
|
||||||
|
|
||||||
|
Objective function:
|
||||||
|
|
||||||
|
$$
|
||||||
|
E = \sum_{i=1}^n (ax_i + by_i - d)^2
|
||||||
|
$$
|
||||||
|
|
||||||
|
Solve for $d$ first: $d =a\bar{x}+b\bar{y}$
|
||||||
|
Plugging back in:
|
||||||
|
|
||||||
|
$$
|
||||||
|
E = \sum_{i=1}^n (a(x_i-\bar{x})+b(y_i-\bar{y}))^2 = \left\|\begin{bmatrix}x_1-\bar{x}&y_1-\bar{y}\\\vdots&\vdots\\x_n-\bar{x}&y_n-\bar{y}\end{bmatrix}\begin{pmatrix}a\\b\end{pmatrix}\right\|^2
|
||||||
|
$$
|
||||||
|
|
||||||
|
We want to find $N$ that minimizes $\|UN\|^2$ subject to $\|N\|^2= 1$
|
||||||
|
Solution is given by the eigenvector of $U^T U$ associated with the smallest eigenvalue
|
||||||
|
|
||||||
|
Drawbacks:
|
||||||
|
|
||||||
|
- Sensitive to outliers
|
||||||
|
|
||||||
|
### Robust fitting
|
||||||
|
|
||||||
|
General approach: find model parameters 𝜃 that minimize
|
||||||
|
|
||||||
|
$$
|
||||||
|
\sum_{i} \rho_{\sigma}(r(x_i;\theta))
|
||||||
|
$$
|
||||||
|
|
||||||
|
$r(x_i;\theta)$: residual of $x_i$ w.r.t. model parameters $\theta$
|
||||||
|
$\rho_{\sigma}$: robust function with scale parameter $\sigma$, e.g., $\rho_{\sigma}(u)=\frac{u^2}{\sigma^2+u^2}$
|
||||||
|
|
||||||
|
Nonlinear optimization problem that must be solved iteratively
|
||||||
|
|
||||||
|
- Least squares solution can be used for initialization
|
||||||
|
- Scale of robust function should be chosen carefully
|
||||||
|
|
||||||
|
Drawbacks:
|
||||||
|
|
||||||
|
- Need to manually choose the robust function and scale parameter
|
||||||
|
|
||||||
|
### RANSAC
|
||||||
|
|
||||||
|
Voting schemes
|
||||||
|
|
||||||
|
Random sample consensus: very general framework for model fitting in the presence of outliers
|
||||||
|
|
||||||
|
Outline:
|
||||||
|
|
||||||
|
- Randomly choose a small initial subset of points
|
||||||
|
- Fit a model to that subset
|
||||||
|
- Find all inlier points that are "close" to the model and reject the rest as outliers
|
||||||
|
- Do this many times and choose the model with the most inliers
|
||||||
|
|
||||||
|
### Hough transform
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -23,4 +23,5 @@ export default {
|
|||||||
CSE559A_L18: "Computer Vision (Lecture 18)",
|
CSE559A_L18: "Computer Vision (Lecture 18)",
|
||||||
CSE559A_L19: "Computer Vision (Lecture 19)",
|
CSE559A_L19: "Computer Vision (Lecture 19)",
|
||||||
CSE559A_L20: "Computer Vision (Lecture 20)",
|
CSE559A_L20: "Computer Vision (Lecture 20)",
|
||||||
|
CSE559A_L21: "Computer Vision (Lecture 21)",
|
||||||
}
|
}
|
||||||
|
|||||||
120
pages/Math416/Math416_L22.md
Normal file
120
pages/Math416/Math416_L22.md
Normal file
@@ -0,0 +1,120 @@
|
|||||||
|
# Math416 Lecture 22
|
||||||
|
|
||||||
|
## Chapter 9: Generalized Cauchy Theorem
|
||||||
|
|
||||||
|
### Winding numbers
|
||||||
|
|
||||||
|
Definition:
|
||||||
|
|
||||||
|
Let $\gamma:[a,b]\to\mathbb{C}$ be a closed curve. The **winding number** of $\gamma$ around $z\in\mathbb{C}$ is defined as
|
||||||
|
|
||||||
|
$$
|
||||||
|
\frac{1}{2\pi i}\Delta(arg(z-z_0),\gamma)
|
||||||
|
$$
|
||||||
|
|
||||||
|
where $\Delta(arg(z-z_0),\gamma)$ is the change in the argument of $z-z_0$ along $\gamma$.
|
||||||
|
|
||||||
|
#### Interior of curve
|
||||||
|
|
||||||
|
The interior of $\gamma$ is the set of points $z\in\mathbb{C}$ such that the winding number of $\gamma$ around $z$ is non-zero.
|
||||||
|
|
||||||
|
$$
|
||||||
|
int_\gamma(z)=\{z\in\mathbb{C}|\frac{1}{2\pi i}\Delta(arg(z-z_0),\gamma)\neq 0\}
|
||||||
|
$$
|
||||||
|
|
||||||
|
#### Contour
|
||||||
|
|
||||||
|
The winding number of a contour $\Gamma$ around $z$ is the sum of the winding numbers of the contours $\gamma_j$ around $z$.
|
||||||
|
|
||||||
|
$$
|
||||||
|
ind_\Gamma(z)=\sum_{j=1}^nn_j ind_{\gamma_j}(z)
|
||||||
|
$$
|
||||||
|
|
||||||
|
A contour is simple if $ind_\gamma(z)=\{0,1\}$ for all $z\in\mathbb{C}\setminus\gamma([a,b])$.
|
||||||
|
|
||||||
|
#### Separation lemma
|
||||||
|
|
||||||
|
Let $\Omega\subseteq \mathbb{C}$ be open, let $K\subset \Omega$ be compact, then $\exists$ a simple contour $\Gamma\subset \Omega\setminus K$ such that
|
||||||
|
|
||||||
|
$$
|
||||||
|
K\subset int_\Gamma(\Gamma)\subset \Omega
|
||||||
|
$$
|
||||||
|
|
||||||
|
Proof:
|
||||||
|
|
||||||
|
First we show that $\exists$ a simple contour $\Gamma\subset \Omega\setminus K$
|
||||||
|
|
||||||
|
Let $0<\delta<dist(K,\partial\Omega)$.
|
||||||
|
|
||||||
|
We draw a grid fo horizontal ad vertical lines each separated from each other by $\delta$.
|
||||||
|
|
||||||
|
Let $S_1,S_2,\dots,S_n$ be the squares that intersect $K$.
|
||||||
|
|
||||||
|
Let $\sigma_j$ be the boundary of $S_j$ traversed in counterclockwise direction.
|
||||||
|
|
||||||
|
Let $\varepsilon$ be the set of edges with exactly one $s_j$ for $j=1,2,\dots,q$.
|
||||||
|
|
||||||
|
Note that $\varepsilon\subseteq \Omega\setminus K$.
|
||||||
|
|
||||||
|
We claim that $\varepsilon$ forms a contour.
|
||||||
|
|
||||||
|
Proof of Claim:
|
||||||
|
|
||||||
|
Say a sequence of edges $E_1,E_2,\dots,E_p$, $E_i\in \varepsilon$. from a chain if terminal points of $E_k$ is the initial point of $E_{k+1}$ for $1\leq k\leq p-1$.
|
||||||
|
|
||||||
|
Say it forms a cycle if inaddition the terminal points of $E_p$ is the initial point of $E_1$.
|
||||||
|
|
||||||
|
Any cycle is a piecewise continuous closed curve.
|
||||||
|
|
||||||
|
We want to show that $\varepsilon$ is a disjoint union of cycles.
|
||||||
|
|
||||||
|
We can prove that every terminal point of an edge in $\varepsilon$ is an initial point of an edge in $\varepsilon$. By case analysis for the state of the four square around the terminal point.
|
||||||
|
|
||||||
|
Let $\gamma=(E_1,E_2,\dots,E_p)$ be a maximal cycle in $\varepsilon$. (Maximal means that we cannot add another edge to it while still having a cycle.)
|
||||||
|
|
||||||
|
Then $\gamma$ is a cycle.
|
||||||
|
|
||||||
|
Look at the terminal point of $E_p$, This is initial point for some edge $E'$, where $E'$ is one of the edges of $\gamma$.
|
||||||
|
|
||||||
|
If $E'$ is not $E_1$, then we can add $E'$ to $\gamma$ to form a larger cycle. Contradiction. (You can do this by case analysis. If there is three edges, then there must be four.)
|
||||||
|
|
||||||
|
Thus $E'=E_1$.
|
||||||
|
|
||||||
|
Thus $\gamma$ is a cycle.
|
||||||
|
|
||||||
|
We can now remove $\gamma$ from $\varepsilon$ to form a new set $\varepsilon'$.
|
||||||
|
|
||||||
|
We can repeat this process to form a disjoint union of cycles using induction.
|
||||||
|
|
||||||
|
Second, we show that $int_\Gamma(\Gamma)\subset \Omega$.
|
||||||
|
|
||||||
|
Let $z_0\in int(S_j)$ for some $1\leq j\leq q$.
|
||||||
|
|
||||||
|
$ind_{S_k}(z_0)=\begin{cases}
|
||||||
|
1 & k=j\\
|
||||||
|
0 & k\neq j
|
||||||
|
\end{cases}$
|
||||||
|
|
||||||
|
Thus
|
||||||
|
|
||||||
|
$$
|
||||||
|
\begin{aligned}
|
||||||
|
\sum_{k=1}^q ind_{S_k}(z_0)&=\sum_{k=1}^q \frac{1}{2\pi i}\int_{\partial S_k}\frac{1}{z-z_0}dz\\
|
||||||
|
&=1\\
|
||||||
|
&=ind_\Gamma(z_0)
|
||||||
|
\end{aligned}
|
||||||
|
$$
|
||||||
|
|
||||||
|
So if $z_0\in int(\bigcup_{j=1}^q S_j)$, then $ind_\Gamma(z_0)=1$.
|
||||||
|
|
||||||
|
And $\bigcup_{j=1}^q S_j\supset K$, so $z_0\in int_\Gamma(K)$.
|
||||||
|
|
||||||
|
Let $z_1\in\mathbb{C}\setminus\left(\bigcup_{j=1}^q S_j\cup\Gamma\right)$.
|
||||||
|
|
||||||
|
Then $ind_{S_k}(z_1)=0$ for all $1\leq k\leq q$.
|
||||||
|
|
||||||
|
Thus $\sum_{k=1}^q ind_{S_k}(z_1)=0=ind_\Gamma(z_1)$.
|
||||||
|
|
||||||
|
QED
|
||||||
|
|
||||||
|
Continue on Generalized Cauchy Theorem next time!!
|
||||||
@@ -25,4 +25,5 @@ export default {
|
|||||||
Math416_L19: "Complex Variables (Lecture 19)",
|
Math416_L19: "Complex Variables (Lecture 19)",
|
||||||
Math416_L20: "Complex Variables (Lecture 20)",
|
Math416_L20: "Complex Variables (Lecture 20)",
|
||||||
Math416_L21: "Complex Variables (Lecture 21)",
|
Math416_L21: "Complex Variables (Lecture 21)",
|
||||||
|
Math416_L22: "Complex Variables (Lecture 22)",
|
||||||
}
|
}
|
||||||
|
|||||||
Reference in New Issue
Block a user