update
This commit is contained in:
@@ -41,12 +41,15 @@ $\beta$ is a hyperparameter that scale the loss of the camera orientation so tha
|
||||
|
||||
### Network architecture
|
||||
|
||||
Based on GoogleNet (SOTA in 2014), but with a few changes:
|
||||
Based on GoogLeNet (SOTA in 2014), but with a few changes:
|
||||
|
||||
- Replace all three softmax classifiers with affine regressors.
|
||||
- Insert another fully connected layer before final regressor of feature size 2048
|
||||
- At test time, normalize the quaternion to unit length.
|
||||
|
||||
<details>
|
||||
<summary>Architecture</summary>
|
||||
|
||||
```python
|
||||
from network import Network
|
||||
|
||||
@@ -259,7 +262,7 @@ class GoogLeNet(Network):
|
||||
.fc(4, relu=False, name='cls3_fc_pose_wpqr'))
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
## Unsupervised Learning of Depth and Ego-Motion From Video
|
||||
|
||||
@@ -267,6 +270,24 @@ class GoogLeNet(Network):
|
||||
|
||||
[link to the paper](https://openaccess.thecvf.com/content_cvpr_2017/papers/Zhou_Unsupervised_Learning_of_CVPR_2017_paper.pdf)
|
||||
|
||||
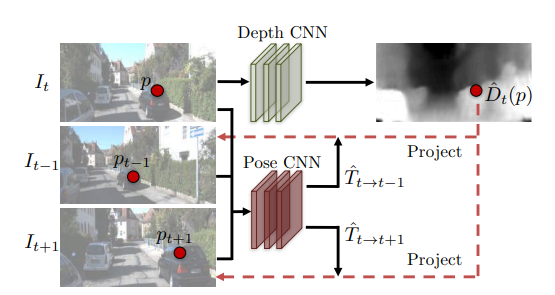
This is a method that estimates both depth and camera pose motion from a single video using CNN.
|
||||
|
||||
Jointly training a single-view depth CNN and a camera pose estimation CNN form unlabelled monocular video sequences.
|
||||
|
||||
|
||||
|
||||
### View synthesis as supervision
|
||||
|
||||
Notice that in mo
|
||||
|
||||
## Unsupervised Monocular Depth Estimation with Left-Right Consistency
|
||||
|
||||
(CVPR 2017)
|
||||
|
||||
[link to the paper](https://arxiv.org/pdf/1609.03677)
|
||||
|
||||
This is a method that use pair of images as Left and Right eye to estimate depth. Increased consistency by flipping the right-left relation.
|
||||
|
||||
## GeoNet
|
||||
|
||||
Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose (CVPR 2018)
|
||||
@@ -283,6 +304,12 @@ Depth Estimation from single monocular image.
|
||||
|
||||
### Rigid structure constructor
|
||||
|
||||
Combines the DepthNet and PoseNet to estimate the depth and camera pose motion from [Unsupervised Learning of Depth and Ego-Motion From Video](#unsupervised-learning-of-depth-and-ego-motion-from-video).
|
||||
|
||||
### Non-rigid motion localizer
|
||||
|
||||
Use [Left-right consistency](#unsupervised-monocular-depth-estimation-with-left-right-consistency) to estimate the non-rigid motion by training the ResFlowNet.
|
||||
|
||||
### Geometric consistency enforcement
|
||||
|
||||
Finally, we use an additional geometric consistency enforcement to handle non-Lambertian surfaces (e.g., metal, plastic, etc.).
|
||||
|
||||
Reference in New Issue
Block a user