update
This commit is contained in:
@@ -41,7 +41,7 @@ void Foo::setValue(int v) {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Memory, Lifetimes, and Scopes
|
### Memory, Lifetimes, and Scopes
|
||||||
|
|
||||||
|
|||||||
@@ -4,12 +4,14 @@
|
|||||||
>
|
>
|
||||||
> This topic is presented by Me. and will be the most detailed one for this course, perhaps.
|
> This topic is presented by Me. and will be the most detailed one for this course, perhaps.
|
||||||
|
|
||||||
This topic is mainly about Depth Estimation from Monocular Images. (Boring, not even RANSAC)
|
|
||||||
|
|
||||||
## PoseNet
|
## PoseNet
|
||||||
|
|
||||||
A Convolutional Network for Real-Time 6-DOF Camera Relocalization (ICCV 2015)
|
A Convolutional Network for Real-Time 6-DOF Camera Relocalization (ICCV 2015)
|
||||||
|
|
||||||
|
Problem solving:
|
||||||
|
|
||||||
|
Camera Pose: Camera position and orientation.
|
||||||
|
|
||||||
[link to the paper](https://arxiv.org/pdf/1505.07427)
|
[link to the paper](https://arxiv.org/pdf/1505.07427)
|
||||||
|
|
||||||
Convolutional neural network (convnet) we train to estimate camera pose directly
|
Convolutional neural network (convnet) we train to estimate camera pose directly
|
||||||
@@ -23,6 +25,242 @@ $$
|
|||||||
|
|
||||||
$q$ is a quaternion, $x$ is a 3D camera position.
|
$q$ is a quaternion, $x$ is a 3D camera position.
|
||||||
|
|
||||||
|
Arbitrary 4D values are easily mapped to legitimate rotations by normalizing them to unit length.
|
||||||
|
|
||||||
|
### Regression function
|
||||||
|
|
||||||
|
Use Stochastic Gradient Descent (SGD) to optimize the network parameters.
|
||||||
|
|
||||||
|
$$
|
||||||
|
loss(I)=\|\hat{x}-x\|_2+\beta\left\|\hat{q}-\frac{q}{\|q\|}\right\|_2
|
||||||
|
$$
|
||||||
|
|
||||||
|
$\hat{x}$ is the estimated camera position, $x$ is the ground truth camera position, $\hat{q}$ is the estimated camera orientation, $q$ is the ground truth camera orientation.
|
||||||
|
|
||||||
|
$\beta$ is a hyperparameter that scale the loss of the camera orientation so that the network can balance on estimating the camera position and orientation approximately the same weight.
|
||||||
|
|
||||||
|
### Network architecture
|
||||||
|
|
||||||
|
Based on GoogleNet (SOTA in 2014), but with a few changes:
|
||||||
|
|
||||||
|
- Replace all three softmax classifiers with affine regressors.
|
||||||
|
- Insert another fully connected layer before final regressor of feature size 2048
|
||||||
|
- At test time, normalize the quaternion to unit length.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from network import Network
|
||||||
|
|
||||||
|
class GoogLeNet(Network):
|
||||||
|
def setup(self):
|
||||||
|
(self.feed('data')
|
||||||
|
.conv(7, 7, 64, 2, 2, name='conv1')
|
||||||
|
.max_pool(3, 3, 2, 2, name='pool1')
|
||||||
|
.lrn(2, 2e-05, 0.75, name='norm1')
|
||||||
|
.conv(1, 1, 64, 1, 1, name='reduction2')
|
||||||
|
.conv(3, 3, 192, 1, 1, name='conv2')
|
||||||
|
.lrn(2, 2e-05, 0.75, name='norm2')
|
||||||
|
.max_pool(3, 3, 2, 2, name='pool2')
|
||||||
|
.conv(1, 1, 96, 1, 1, name='icp1_reduction1')
|
||||||
|
.conv(3, 3, 128, 1, 1, name='icp1_out1'))
|
||||||
|
|
||||||
|
(self.feed('pool2')
|
||||||
|
.conv(1, 1, 16, 1, 1, name='icp1_reduction2')
|
||||||
|
.conv(5, 5, 32, 1, 1, name='icp1_out2'))
|
||||||
|
|
||||||
|
(self.feed('pool2')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp1_pool')
|
||||||
|
.conv(1, 1, 32, 1, 1, name='icp1_out3'))
|
||||||
|
|
||||||
|
(self.feed('pool2')
|
||||||
|
.conv(1, 1, 64, 1, 1, name='icp1_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp1_out0',
|
||||||
|
'icp1_out1',
|
||||||
|
'icp1_out2',
|
||||||
|
'icp1_out3')
|
||||||
|
.concat(3, name='icp2_in')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='icp2_reduction1')
|
||||||
|
.conv(3, 3, 192, 1, 1, name='icp2_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp2_in')
|
||||||
|
.conv(1, 1, 32, 1, 1, name='icp2_reduction2')
|
||||||
|
.conv(5, 5, 96, 1, 1, name='icp2_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp2_in')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp2_pool')
|
||||||
|
.conv(1, 1, 64, 1, 1, name='icp2_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp2_in')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='icp2_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp2_out0',
|
||||||
|
'icp2_out1',
|
||||||
|
'icp2_out2',
|
||||||
|
'icp2_out3')
|
||||||
|
.concat(3, name='icp2_out')
|
||||||
|
.max_pool(3, 3, 2, 2, name='icp3_in')
|
||||||
|
.conv(1, 1, 96, 1, 1, name='icp3_reduction1')
|
||||||
|
.conv(3, 3, 208, 1, 1, name='icp3_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp3_in')
|
||||||
|
.conv(1, 1, 16, 1, 1, name='icp3_reduction2')
|
||||||
|
.conv(5, 5, 48, 1, 1, name='icp3_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp3_in')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp3_pool')
|
||||||
|
.conv(1, 1, 64, 1, 1, name='icp3_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp3_in')
|
||||||
|
.conv(1, 1, 192, 1, 1, name='icp3_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp3_out0',
|
||||||
|
'icp3_out1',
|
||||||
|
'icp3_out2',
|
||||||
|
'icp3_out3')
|
||||||
|
.concat(3, name='icp3_out')
|
||||||
|
.avg_pool(5, 5, 3, 3, padding='VALID', name='cls1_pool')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='cls1_reduction_pose')
|
||||||
|
.fc(1024, name='cls1_fc1_pose')
|
||||||
|
.fc(3, relu=False, name='cls1_fc_pose_xyz'))
|
||||||
|
|
||||||
|
(self.feed('cls1_fc1_pose')
|
||||||
|
.fc(4, relu=False, name='cls1_fc_pose_wpqr'))
|
||||||
|
|
||||||
|
(self.feed('icp3_out')
|
||||||
|
.conv(1, 1, 112, 1, 1, name='icp4_reduction1')
|
||||||
|
.conv(3, 3, 224, 1, 1, name='icp4_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp3_out')
|
||||||
|
.conv(1, 1, 24, 1, 1, name='icp4_reduction2')
|
||||||
|
.conv(5, 5, 64, 1, 1, name='icp4_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp3_out')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp4_pool')
|
||||||
|
.conv(1, 1, 64, 1, 1, name='icp4_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp3_out')
|
||||||
|
.conv(1, 1, 160, 1, 1, name='icp4_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp4_out0',
|
||||||
|
'icp4_out1',
|
||||||
|
'icp4_out2',
|
||||||
|
'icp4_out3')
|
||||||
|
.concat(3, name='icp4_out')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='icp5_reduction1')
|
||||||
|
.conv(3, 3, 256, 1, 1, name='icp5_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp4_out')
|
||||||
|
.conv(1, 1, 24, 1, 1, name='icp5_reduction2')
|
||||||
|
.conv(5, 5, 64, 1, 1, name='icp5_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp4_out')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp5_pool')
|
||||||
|
.conv(1, 1, 64, 1, 1, name='icp5_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp4_out')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='icp5_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp5_out0',
|
||||||
|
'icp5_out1',
|
||||||
|
'icp5_out2',
|
||||||
|
'icp5_out3')
|
||||||
|
.concat(3, name='icp5_out')
|
||||||
|
.conv(1, 1, 144, 1, 1, name='icp6_reduction1')
|
||||||
|
.conv(3, 3, 288, 1, 1, name='icp6_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp5_out')
|
||||||
|
.conv(1, 1, 32, 1, 1, name='icp6_reduction2')
|
||||||
|
.conv(5, 5, 64, 1, 1, name='icp6_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp5_out')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp6_pool')
|
||||||
|
.conv(1, 1, 64, 1, 1, name='icp6_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp5_out')
|
||||||
|
.conv(1, 1, 112, 1, 1, name='icp6_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp6_out0',
|
||||||
|
'icp6_out1',
|
||||||
|
'icp6_out2',
|
||||||
|
'icp6_out3')
|
||||||
|
.concat(3, name='icp6_out')
|
||||||
|
.avg_pool(5, 5, 3, 3, padding='VALID', name='cls2_pool')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='cls2_reduction_pose')
|
||||||
|
.fc(1024, name='cls2_fc1')
|
||||||
|
.fc(3, relu=False, name='cls2_fc_pose_xyz'))
|
||||||
|
|
||||||
|
(self.feed('cls2_fc1')
|
||||||
|
.fc(4, relu=False, name='cls2_fc_pose_wpqr'))
|
||||||
|
|
||||||
|
(self.feed('icp6_out')
|
||||||
|
.conv(1, 1, 160, 1, 1, name='icp7_reduction1')
|
||||||
|
.conv(3, 3, 320, 1, 1, name='icp7_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp6_out')
|
||||||
|
.conv(1, 1, 32, 1, 1, name='icp7_reduction2')
|
||||||
|
.conv(5, 5, 128, 1, 1, name='icp7_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp6_out')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp7_pool')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='icp7_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp6_out')
|
||||||
|
.conv(1, 1, 256, 1, 1, name='icp7_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp7_out0',
|
||||||
|
'icp7_out1',
|
||||||
|
'icp7_out2',
|
||||||
|
'icp7_out3')
|
||||||
|
.concat(3, name='icp7_out')
|
||||||
|
.max_pool(3, 3, 2, 2, name='icp8_in')
|
||||||
|
.conv(1, 1, 160, 1, 1, name='icp8_reduction1')
|
||||||
|
.conv(3, 3, 320, 1, 1, name='icp8_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp8_in')
|
||||||
|
.conv(1, 1, 32, 1, 1, name='icp8_reduction2')
|
||||||
|
.conv(5, 5, 128, 1, 1, name='icp8_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp8_in')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp8_pool')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='icp8_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp8_in')
|
||||||
|
.conv(1, 1, 256, 1, 1, name='icp8_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp8_out0',
|
||||||
|
'icp8_out1',
|
||||||
|
'icp8_out2',
|
||||||
|
'icp8_out3')
|
||||||
|
.concat(3, name='icp8_out')
|
||||||
|
.conv(1, 1, 192, 1, 1, name='icp9_reduction1')
|
||||||
|
.conv(3, 3, 384, 1, 1, name='icp9_out1'))
|
||||||
|
|
||||||
|
(self.feed('icp8_out')
|
||||||
|
.conv(1, 1, 48, 1, 1, name='icp9_reduction2')
|
||||||
|
.conv(5, 5, 128, 1, 1, name='icp9_out2'))
|
||||||
|
|
||||||
|
(self.feed('icp8_out')
|
||||||
|
.max_pool(3, 3, 1, 1, name='icp9_pool')
|
||||||
|
.conv(1, 1, 128, 1, 1, name='icp9_out3'))
|
||||||
|
|
||||||
|
(self.feed('icp8_out')
|
||||||
|
.conv(1, 1, 384, 1, 1, name='icp9_out0'))
|
||||||
|
|
||||||
|
(self.feed('icp9_out0',
|
||||||
|
'icp9_out1',
|
||||||
|
'icp9_out2',
|
||||||
|
'icp9_out3')
|
||||||
|
.concat(3, name='icp9_out')
|
||||||
|
.avg_pool(7, 7, 1, 1, padding='VALID', name='cls3_pool')
|
||||||
|
.fc(2048, name='cls3_fc1_pose')
|
||||||
|
.fc(3, relu=False, name='cls3_fc_pose_xyz'))
|
||||||
|
|
||||||
|
(self.feed('cls3_fc1_pose')
|
||||||
|
.fc(4, relu=False, name='cls3_fc_pose_wpqr'))
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Unsupervised Learning of Depth and Ego-Motion From Video
|
## Unsupervised Learning of Depth and Ego-Motion From Video
|
||||||
|
|
||||||
(CVPR 2017)
|
(CVPR 2017)
|
||||||
@@ -33,6 +271,10 @@ $q$ is a quaternion, $x$ is a 3D camera position.
|
|||||||
|
|
||||||
Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose (CVPR 2018)
|
Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose (CVPR 2018)
|
||||||
|
|
||||||
|
Problem solving:
|
||||||
|
|
||||||
|
Depth Estimation from single monocular image.
|
||||||
|
|
||||||
[link to the paper](https://openaccess.thecvf.com/content_cvpr_2018/papers/Yin_GeoNet_Unsupervised_Learning_CVPR_2018_paper.pdf)
|
[link to the paper](https://openaccess.thecvf.com/content_cvpr_2018/papers/Yin_GeoNet_Unsupervised_Learning_CVPR_2018_paper.pdf)
|
||||||
|
|
||||||
[link to the repository](https://github.com/yzcjtr/GeoNet)
|
[link to the repository](https://github.com/yzcjtr/GeoNet)
|
||||||
|
|||||||
@@ -632,7 +632,7 @@ $B$ performs a measurement on the combined state of the one qubit and the entang
|
|||||||
|
|
||||||
$B$ decodes the result and obtains the 2 classical bits sent by $A$.
|
$B$ decodes the result and obtains the 2 classical bits sent by $A$.
|
||||||
|
|
||||||

|
Superdense coding](https://notenextra.trance-0.com/Math401/Superdense_coding.png)
|
||||||
|
|
||||||
## Section 4: Quantum automorphisms and dynamics
|
## Section 4: Quantum automorphisms and dynamics
|
||||||
|
|
||||||
|
|||||||
@@ -38,7 +38,7 @@ Proof:
|
|||||||
|
|
||||||
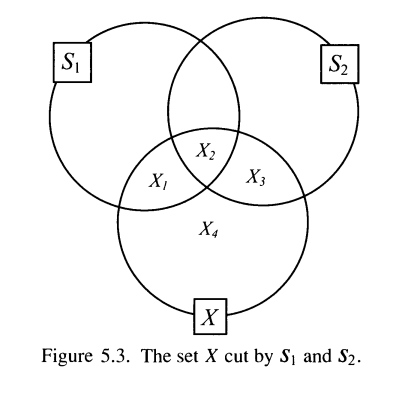
Suppose $S_1, S_2$ is a measurable, and we need to show that $S_1\cup S_2$ is measurable. Given $X$, need to show that
|
Suppose $S_1, S_2$ is a measurable, and we need to show that $S_1\cup S_2$ is measurable. Given $X$, need to show that
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
$$
|
$$
|
||||||
m_e(X) = m_e(X_1\cup X_2\cup X_3)+ m_e(X_4)
|
m_e(X) = m_e(X_1\cup X_2\cup X_3)+ m_e(X_4)
|
||||||
|
|||||||
Reference in New Issue
Block a user