47 lines
1.4 KiB
Markdown
47 lines
1.4 KiB
Markdown
# CSE5519 Advances in Computer Vision (Topic E: 2021 and before: Deep Learning for Geometric Computer Vision)
|
|
|
|
> [!NOTE]
|
|
>
|
|
> This topic is presented by Me. and will be the most detailed one for this course, perhaps.
|
|
|
|
This topic is mainly about Depth Estimation from Monocular Images. (Boring, not even RANSAC)
|
|
|
|
## PoseNet
|
|
|
|
A Convolutional Network for Real-Time 6-DOF Camera Relocalization (ICCV 2015)
|
|
|
|
[link to the paper](https://arxiv.org/pdf/1505.07427)
|
|
|
|
Convolutional neural network (convnet) we train to estimate camera pose directly
|
|
from a monocular image, $I$. Our network outputs a pose
|
|
vector $p$, given by a 3D camera position $x$ and orientation
|
|
represented by quaternion q:
|
|
|
|
$$
|
|
p = [x, q]
|
|
$$
|
|
|
|
$q$ is a quaternion, $x$ is a 3D camera position.
|
|
|
|
## Unsupervised Learning of Depth and Ego-Motion From Video
|
|
|
|
(CVPR 2017)
|
|
|
|
[link to the paper](https://openaccess.thecvf.com/content_cvpr_2017/papers/Zhou_Unsupervised_Learning_of_CVPR_2017_paper.pdf)
|
|
|
|
## GeoNet
|
|
|
|
Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose (CVPR 2018)
|
|
|
|
[link to the paper](https://openaccess.thecvf.com/content_cvpr_2018/papers/Yin_GeoNet_Unsupervised_Learning_CVPR_2018_paper.pdf)
|
|
|
|
[link to the repository](https://github.com/yzcjtr/GeoNet)
|
|
|
|
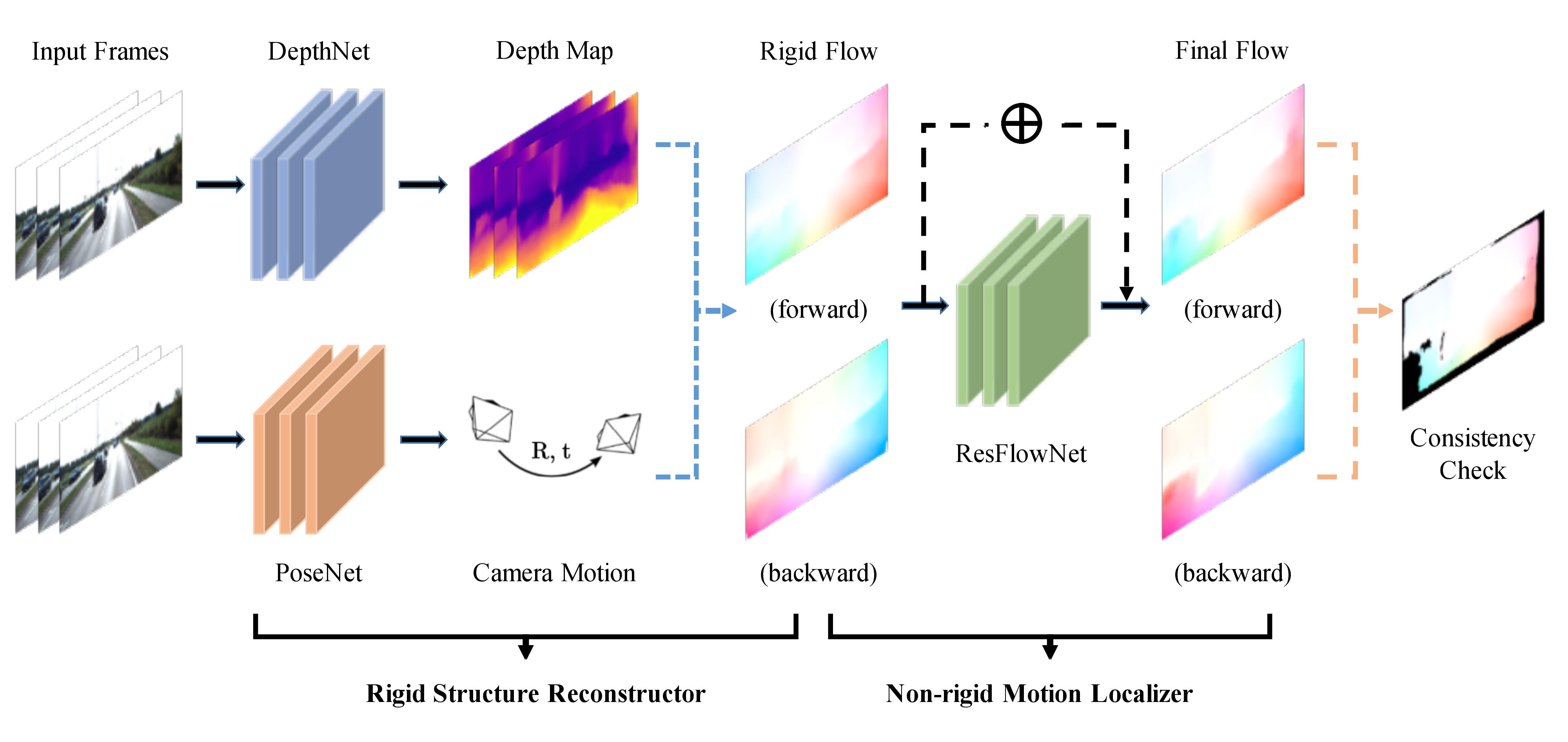
|
|
|
|
### Rigid structure constructor
|
|
|
|
### Non-rigid motion localizer
|
|
|
|
### Geometric consistency enforcement
|